出典: 量子ビットLi Feifei のチーム **身体化されたインテリジェンス** の最新の成果は次のとおりです。大型モデルはロボットに接続されており、追加のデータやトレーニングを必要とせずに、複雑な指示を特定の行動計画に変換します。 それ以降、人間は自然言語を自由に使用してロボットに次のような指示を与えることができるようになります。> 一番上の引き出しを開けて、花瓶に注意してください! 大規模言語モデル + 視覚言語モデルは、3D 空間から回避する必要があるターゲットと障害物を分析し、ロボットの行動計画を立てるのに役立ちます。 そして、重要な点は、**現実世界**のロボットが「トレーニング」なしでこのタスクを直接実行できるということです。 この新しい手法は、ゼロサンプルの日常作業タスク軌跡合成を実現します。つまり、ロボットがこれまで見たことのないタスクをデモンストレーションすることなく一度に実行できるようになります。操作可能なオブジェクトもオープンになっており、事前に範囲を区切る必要がなく、ボトルを開けてスイッチを押し、充電ケーブルを抜くだけで済みます。 現在、プロジェクトのホームページと論文はオンラインで公開されており、コードは間もなく公開される予定で、学術コミュニティの幅広い関心を呼んでいます。 元マイクロソフトの研究者は次のようにコメントしました: この研究は人工知能システムの最も重要かつ複雑な最前線にあります。 ロボット研究コミュニティに特有のことですが、同僚の中には動作計画の分野に新しい世界が開かれたと語る人もいます。 AIの危険性を認識していなかった人もいますが、今回のロボットとAIの組み合わせの研究により、その見方が変わりました。## **ロボットはどのようにして人間の音声を直接理解できるのでしょうか? **Li Feifei 氏のチームはシステムを VoxPoser と名付けました。下の図に示すように、その原理は非常に単純です。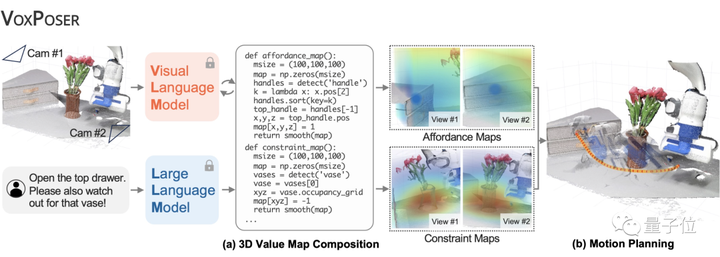 まず、環境情報 (カメラで RGB-D 画像を収集) と実行したい自然言語命令が与えられます。次に、LLM (Large Language Model) がこれらの内容に基づいてコードを記述し、生成されたコードは VLM (Visual Language Model) と対話して、システムが対応する操作命令マップ、つまり **3D Value Map** を生成するようにガイドします。 いわゆる 3D バリュー マップは、アフォーダンス マップと制約マップの総称であり、**「どこで行動するか」** と「どのように行動するか」** の両方を示します。 このようにして、アクション プランナーが移動され、生成された 3D マップがその目的関数として使用され、実行される最終的な操作軌跡が合成されます。このプロセスから、従来の方法と比較して、追加の事前トレーニングが必要であることがわかります。この方法は、大規模なモデルを使用してロボットが環境と対話する方法をガイドするため、ロボットのトレーニングデータの不足の問題を直接解決します。さらに、この特徴があるからこそゼロサンプル機能も実現しており、上記の基本プロセスをマスターすれば、どんなタスクでもこなすことが可能です。具体的な実装では、著者は VoxPoser のアイデアを最適化問題、つまり次の複雑な式に変換しました。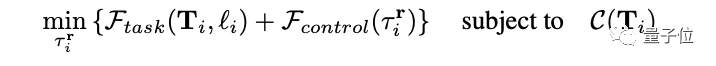 人間による指示の範囲は広く、状況の理解が必要であることを考慮して、指示は多くのサブタスクに分解されています。たとえば、冒頭の最初の例は、「引き出しのハンドルをつかむ」と「引き出しを引く」で構成されています。引き出し"。VoxPoser が達成したいのは、各サブタスクを最適化し、一連のロボットの軌道を取得し、最終的に総作業負荷と作業時間を最小限に抑えることです。LLM と VLM を使用して言語命令を 3D マップにマッピングするプロセスにおいて、システムは言語が豊かな意味空間を伝えることができると考えているため、「**対象エンティティ**(対象エンティティ)」を使用してロボットを次の場所に誘導します。つまり、3DValue マップでマークされた値を通じて、どのオブジェクトが「魅力的」であり、それらのオブジェクトが「反発的」であるかを反映します。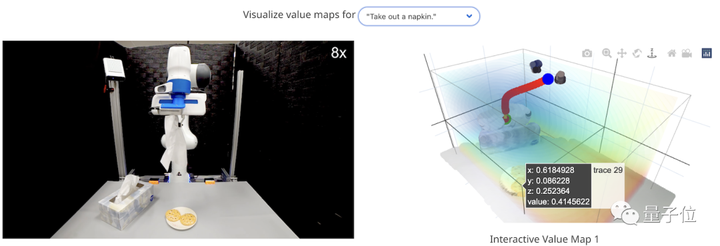 冒頭の例を引き続き使用します🌰、引き出しは「引き寄せ」、花瓶は「反発」します。もちろん、これらの値をどのように生成するかは、大規模言語モデルの理解能力に依存します。最終的な軌道合成プロセスでは、言語モデルの出力はタスク全体を通じて一定のままであるため、その出力をキャッシュし、閉ループの視覚的フィードバックを使用して生成されたコードを再評価することで、外乱に遭遇したときに迅速に再評価できます。したがって、VoxPoser は強力な抗干渉能力を備えています。### △ 古紙は青いトレイに入れます以下は、実際の環境とシミュレートされた環境における VoxPoser のパフォーマンス (平均成功率で測定) です。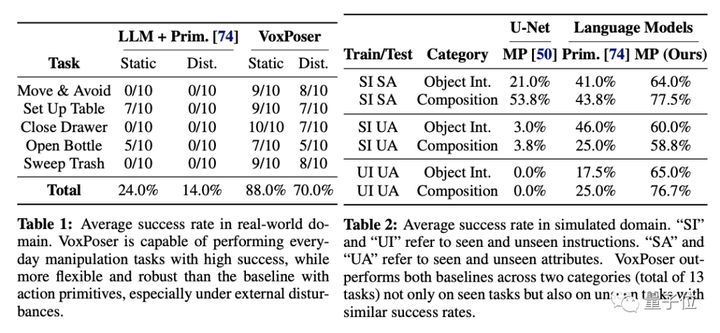 環境(気を散らすものの有無、指示が見えるかどうか)に関係なく、プリミティブベースのベースラインタスクよりも大幅に高いことがわかります。最後に、著者は、VoxPoser が **4 つの「緊急能力」** を生み出したことを知って嬉しい驚きを覚えました。(1) 質量が未知の 2 つのブロックが与えられ、ロボットにツールを使用して物理実験を実行させ、どちらのブロックがより重いかを決定するなどの物理的特性を評価します。(2) 食器をセットする作業などの行動常識的推論により、ロボットに「私は左利きです」と伝えられ、文脈を通じてその意味を理解できます。(3) きめ細かい補正 例えば「急須に蓋をする」などの精度が要求される作業において、「1cmずれていますね」などとロボットに細かく指示を出して動作を修正することができます。(4) 引き出しを正確に半分に開けるようロボットに要求するなど、視覚に基づく多段階の操作 物体モデルの欠如による情報不足によりロボットがそのようなタスクを実行できない可能性がありますが、VoxPoser は提案できます。視覚的なフィードバックに基づいた多段階の操作戦略、つまり、最初にハンドルの変位を記録しながら引き出しを完全に開き、次に要件を満たすために引き出しを中間点まで押し戻します。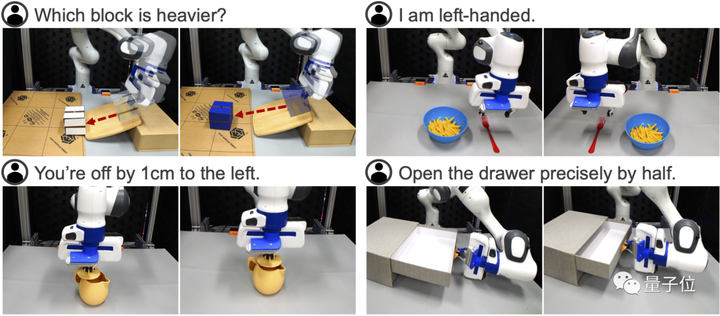## **フェイフェイ・リー: コンピューター ビジョンの 3 人の北極星**約 1 年前、Li Feifei は米国芸術科学アカデミー誌に記事を書き、コンピューター ビジョンの発展には 3 つの方向性があると指摘しました。* 身体化されたAI* 視覚的推論* シーンの理解 リー・フェイフェイ氏は、身体化された知能とは人型ロボットだけを指すのではなく、宇宙を移動できる有形の知的機械はすべて人工知能の一形態であると考えています。ImageNet が現実世界のさまざまな画像を表現することを目的としているのと同じように、身体化インテリジェンスの研究では、洗濯物をたたむことから新しい都市の探索に至るまで、人間の複雑で多様なタスクに対処する必要があります。これらのタスクを実行するための指示に従うには視覚が必要ですが、視覚だけでなく、シーン内の 3 次元の関係を理解するための視覚的推論も必要です。最後に、機械は人間の意図や社会的関係を含め、現場にいる人々を理解する必要があります。たとえば、冷蔵庫を開ける人を見ればお腹が空いていることがわかりますし、子供が大人の膝の上に座っているのを見れば親子であることがわかります。ロボットと大型モデルを組み合わせることは、これらの問題を解決する 1 つの方法にすぎない可能性があります。 Li Feifei 氏に加えて、MIT で博士号を取得し卒業し、現在はスタンフォード大学の助教授を務める清華耀播の同窓生 **Wu Jiajun** 氏もこの研究に参加しました。 論文の筆頭著者である **Wenlong Huang** は現在スタンフォード大学の博士課程の学生で、Google でのインターンシップ中に PaLM-E 研究に参加しました。 用紙のアドレス:プロジェクトのホームページ:参考リンク:[1][1]


李飛飛の「体現された知性」の新たな成果!ロボットは大型モデルに接続して人間の音声を直接理解し、事前トレーニングなしで複雑な指示を完了できます。
出典: 量子ビット
Li Feifei のチーム 身体化されたインテリジェンス の最新の成果は次のとおりです。
大型モデルはロボットに接続されており、追加のデータやトレーニングを必要とせずに、複雑な指示を特定の行動計画に変換します。
操作可能なオブジェクトもオープンになっており、事前に範囲を区切る必要がなく、ボトルを開けてスイッチを押し、充電ケーブルを抜くだけで済みます。
**ロボットはどのようにして人間の音声を直接理解できるのでしょうか? **
Li Feifei 氏のチームはシステムを VoxPoser と名付けました。下の図に示すように、その原理は非常に単純です。
次に、LLM (Large Language Model) がこれらの内容に基づいてコードを記述し、生成されたコードは VLM (Visual Language Model) と対話して、システムが対応する操作命令マップ、つまり 3D Value Map を生成するようにガイドします。
このプロセスから、従来の方法と比較して、追加の事前トレーニングが必要であることがわかります。この方法は、大規模なモデルを使用してロボットが環境と対話する方法をガイドするため、ロボットのトレーニングデータの不足の問題を直接解決します。
さらに、この特徴があるからこそゼロサンプル機能も実現しており、上記の基本プロセスをマスターすれば、どんなタスクでもこなすことが可能です。
具体的な実装では、著者は VoxPoser のアイデアを最適化問題、つまり次の複雑な式に変換しました。
VoxPoser が達成したいのは、各サブタスクを最適化し、一連のロボットの軌道を取得し、最終的に総作業負荷と作業時間を最小限に抑えることです。
LLM と VLM を使用して言語命令を 3D マップにマッピングするプロセスにおいて、システムは言語が豊かな意味空間を伝えることができると考えているため、「対象エンティティ(対象エンティティ)」を使用してロボットを次の場所に誘導します。つまり、3DValue マップでマークされた値を通じて、どのオブジェクトが「魅力的」であり、それらのオブジェクトが「反発的」であるかを反映します。
もちろん、これらの値をどのように生成するかは、大規模言語モデルの理解能力に依存します。
最終的な軌道合成プロセスでは、言語モデルの出力はタスク全体を通じて一定のままであるため、その出力をキャッシュし、閉ループの視覚的フィードバックを使用して生成されたコードを再評価することで、外乱に遭遇したときに迅速に再評価できます。
したがって、VoxPoser は強力な抗干渉能力を備えています。
以下は、実際の環境とシミュレートされた環境における VoxPoser のパフォーマンス (平均成功率で測定) です。
最後に、著者は、VoxPoser が 4 つの「緊急能力」 を生み出したことを知って嬉しい驚きを覚えました。
(1) 質量が未知の 2 つのブロックが与えられ、ロボットにツールを使用して物理実験を実行させ、どちらのブロックがより重いかを決定するなどの物理的特性を評価します。
(2) 食器をセットする作業などの行動常識的推論により、ロボットに「私は左利きです」と伝えられ、文脈を通じてその意味を理解できます。
(3) きめ細かい補正 例えば「急須に蓋をする」などの精度が要求される作業において、「1cmずれていますね」などとロボットに細かく指示を出して動作を修正することができます。
(4) 引き出しを正確に半分に開けるようロボットに要求するなど、視覚に基づく多段階の操作 物体モデルの欠如による情報不足によりロボットがそのようなタスクを実行できない可能性がありますが、VoxPoser は提案できます。視覚的なフィードバックに基づいた多段階の操作戦略、つまり、最初にハンドルの変位を記録しながら引き出しを完全に開き、次に要件を満たすために引き出しを中間点まで押し戻します。
フェイフェイ・リー: コンピューター ビジョンの 3 人の北極星
約 1 年前、Li Feifei は米国芸術科学アカデミー誌に記事を書き、コンピューター ビジョンの発展には 3 つの方向性があると指摘しました。
ImageNet が現実世界のさまざまな画像を表現することを目的としているのと同じように、身体化インテリジェンスの研究では、洗濯物をたたむことから新しい都市の探索に至るまで、人間の複雑で多様なタスクに対処する必要があります。
これらのタスクを実行するための指示に従うには視覚が必要ですが、視覚だけでなく、シーン内の 3 次元の関係を理解するための視覚的推論も必要です。
最後に、機械は人間の意図や社会的関係を含め、現場にいる人々を理解する必要があります。たとえば、冷蔵庫を開ける人を見ればお腹が空いていることがわかりますし、子供が大人の膝の上に座っているのを見れば親子であることがわかります。
ロボットと大型モデルを組み合わせることは、これらの問題を解決する 1 つの方法にすぎない可能性があります。